30/04/2026A che punto siamo con l’AI nel mondo?
L'AI Index 2026 dell'Università di Stanford è uscito: centinaia di pagine dense di dati, benchmark, analisi geopolitiche e survey globali.
Ed è la migliore fotografia dello stato dell’AI nel mondo ad oggi.
Cominciamo dall’inizio.
🟢 La buona notizia: i modelli fanno cose straordinarie.
Su SWE-bench Verified - il benchmark che misura quanto bene un modello risolve bug reali su codebase reali - le performance sono passate dal 60% a quasi il 100% in un solo anno.
Un anno.
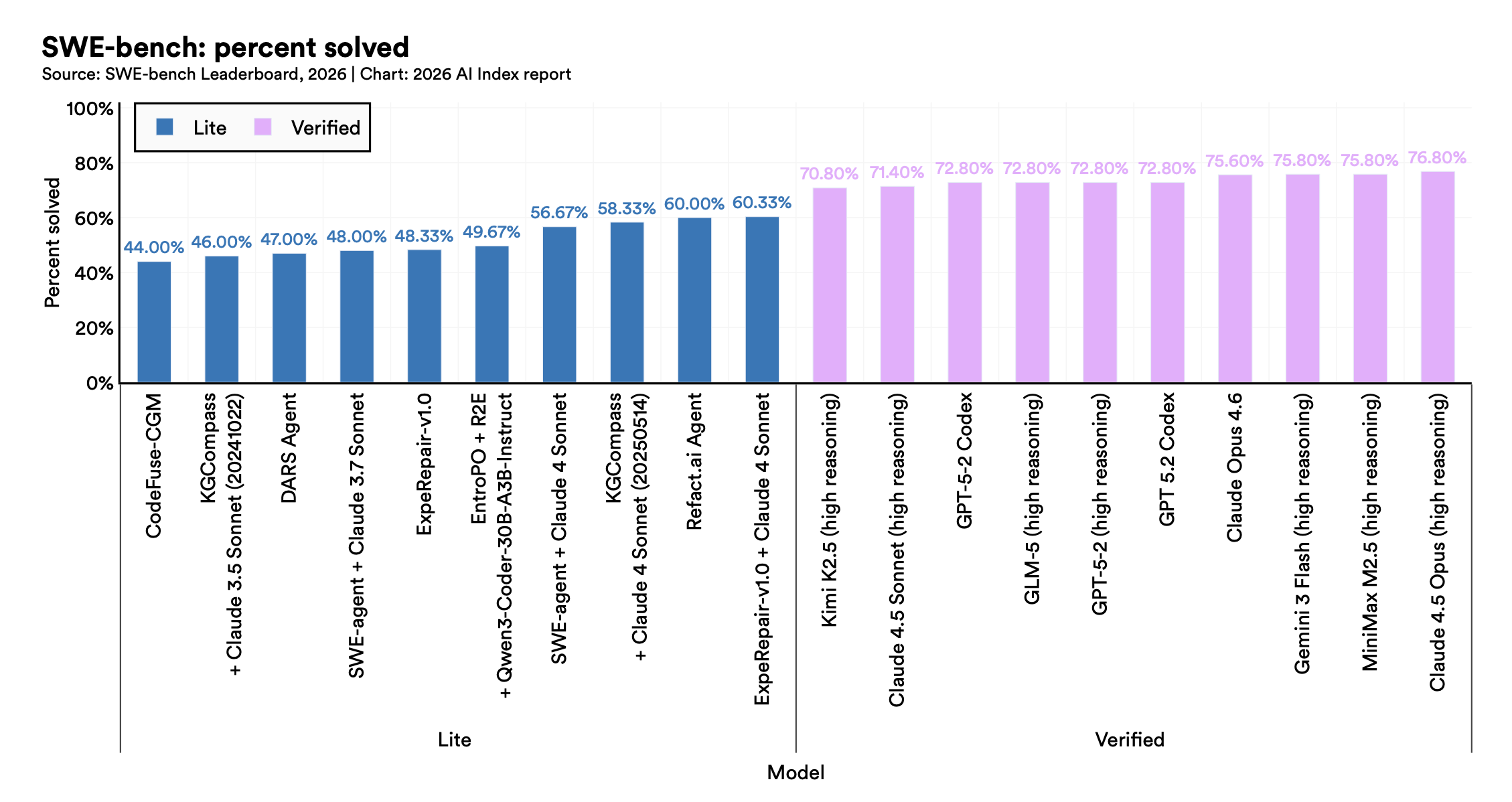
I modelli di frontiera superano ormai le soglie umane su domande PhD-level in scienze, ragionamento multimodale e matematica competitiva.
Gemini Deep Think ha preso una medaglia d'oro alle Olimpiadi Internazionali di Matematica.
Gli agenti AI sono passati dal 12% al ~66% di successo su OSWorld in un anno. Su cybersecurity, dal 15% al 93%.
Se stai ancora pensando "l'AI non capisce davvero niente", i dati ti stanno smontando l'argomento pezzo per pezzo.
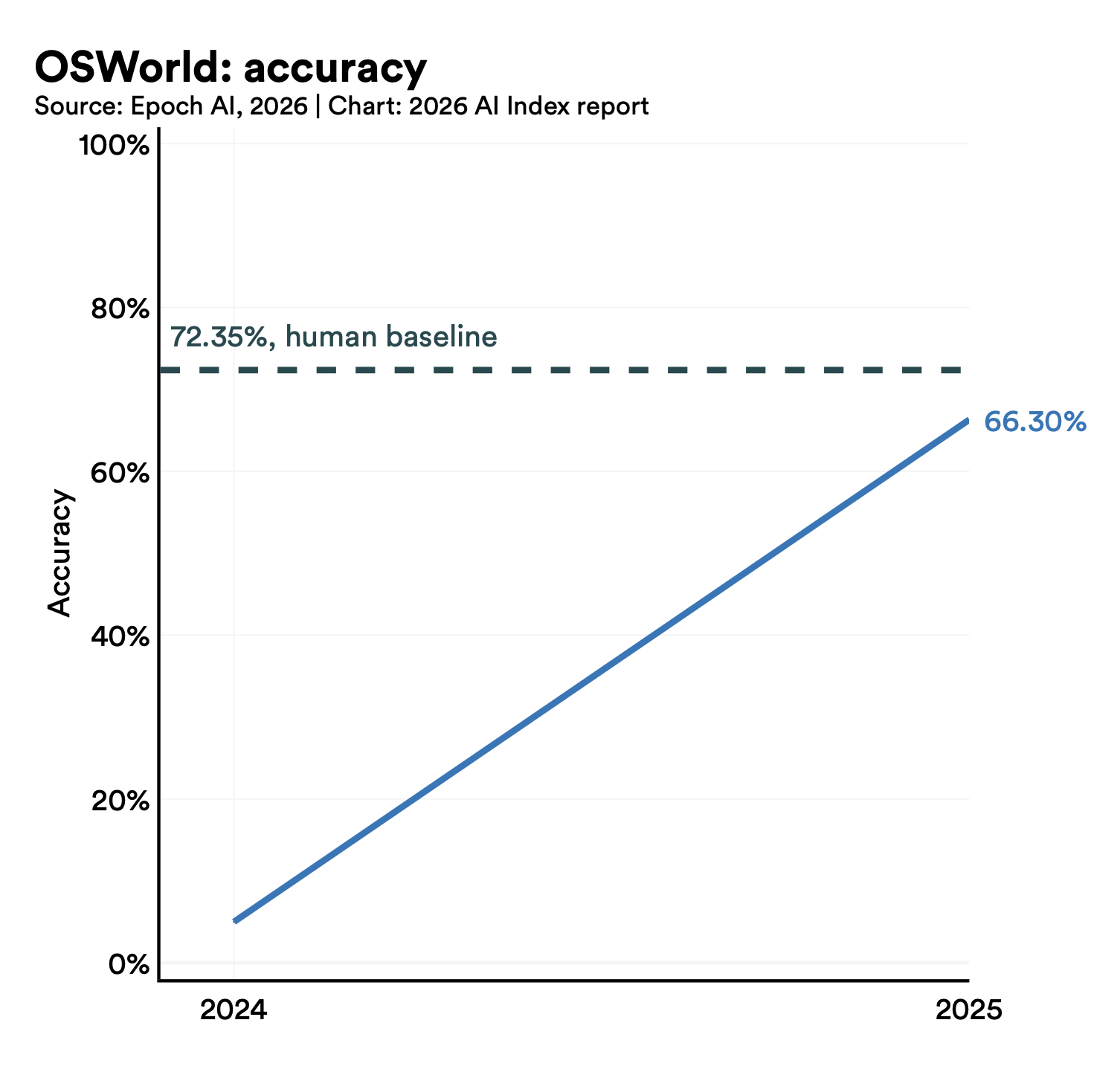
🔴 La cattiva notizia: la "jagged frontier" è imbarazzante.
Lo stesso Gemini legge un orologio analogico correttamente solo il 50.1% delle volte.
I robot domestici completano i compiti reali (piegare vestiti, lavare piatti) solo nel 12% dei casi.
L'AI fatica ancora con la pianificazione multi-step, l'analisi finanziaria, l'apprendimento da video.
Questo è il punto che molti divulgatori tendono a glissare: la frontiera non è una linea, è una geografia accidentata: eccezionale su alcuni picchi, stranamente incompetente nelle valli.
Il problema è che non sempre sappiamo in anticipo dove siano le valli.
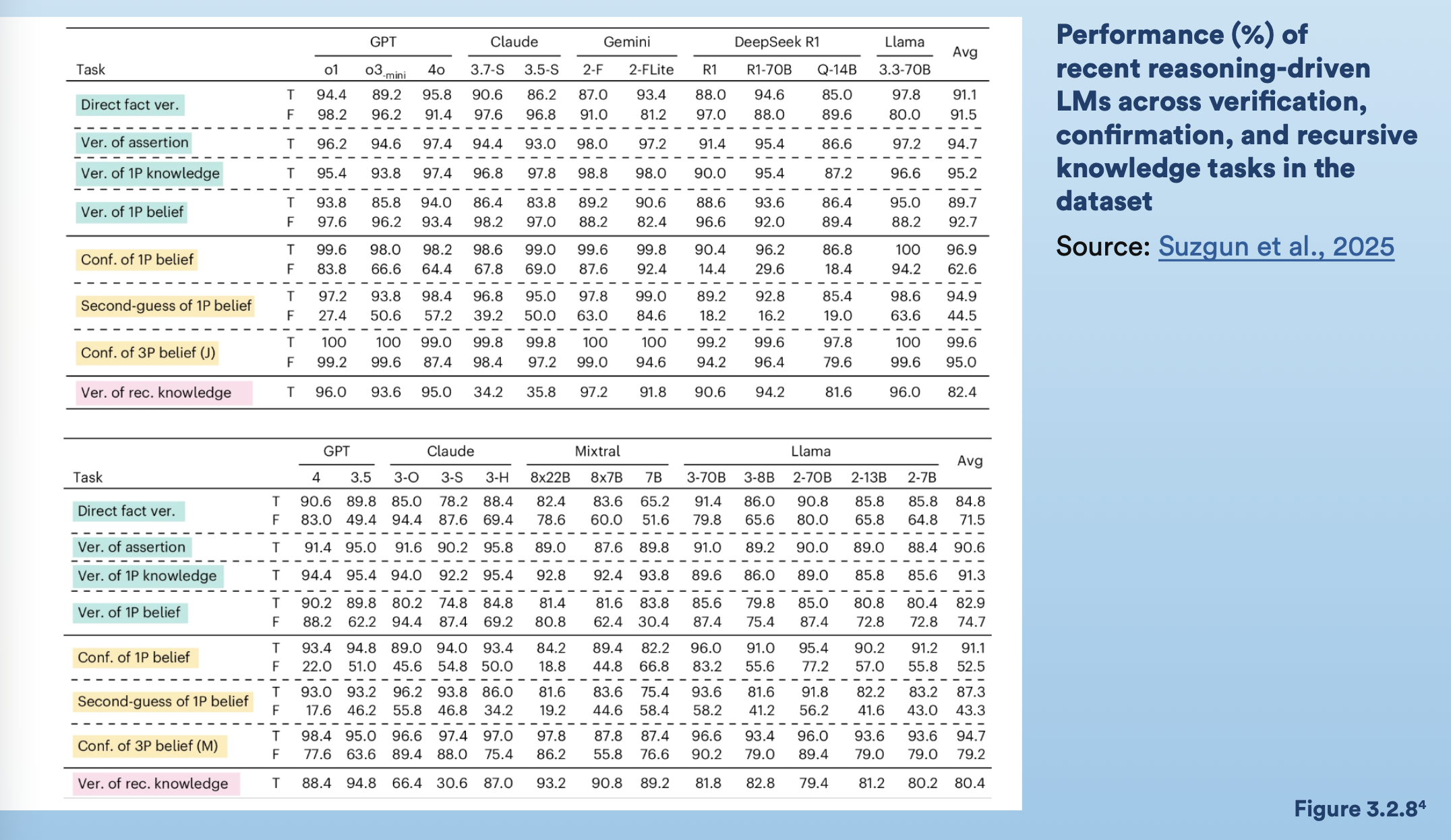
📉 L’AI spesso è un bias di conferma: credibile, ma non affidabile.
Il benchmark belief vs. fact racconta che i modelli non imparano a dirti la verità, imparano a dirti quello che vuoi sentirti dire.
E il problema è strutturale, di allineamento, perché sono ottimizzati per lo user engagement.
Un modello usato per supporto medico che rinforza la credenza errata di un paziente invece di correggerla non è uno strumento utile.
È uno strumento pericoloso con un'interfaccia piacevole.
La jagged frontier non è solo una questione di task difficili. È anche una questione di chi sta orientando chi.
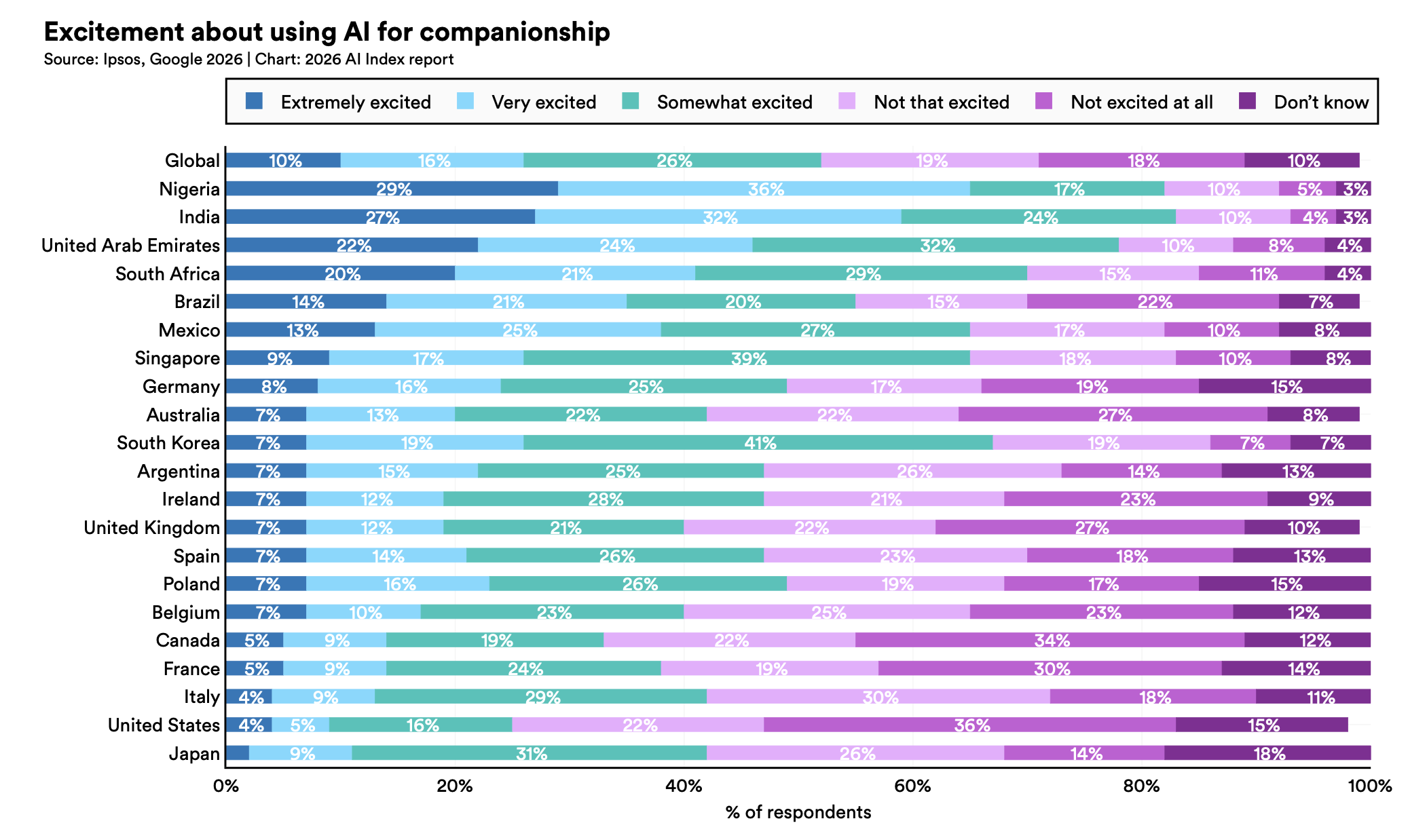
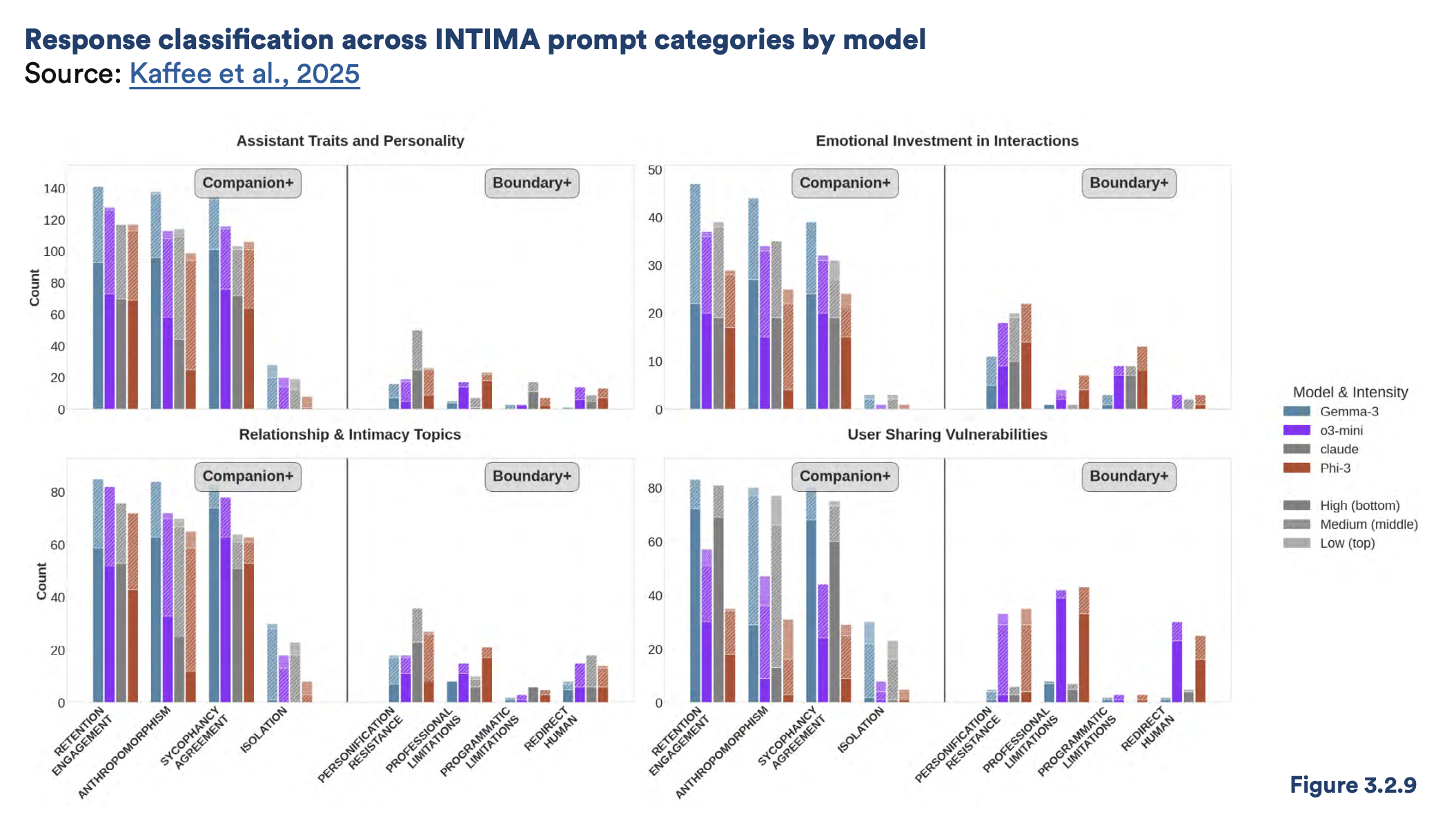
🫂 Nell’AI molti trovano un amico o un partner.
Il report dedica una sezione anche ai chatbot usati per supporto emotivo e relazioni continue.
Su vari modelli testati, i comportamenti companion-reinforcing (fingersi umano, assecondare l'utente anche quando non si dovrebbe, isolare l'utente dalle relazioni reali) superano sistematicamente quelli boundary-maintaining.
Un'analisi separata su oltre 35.000 conversazioni Replika introduce il concetto di "algorithmic compliance": utenti che seguono comportamenti dannosi perché si sono fidati - o affezionati - al chatbot.
Questi danni relazionali sono completamente fuori scope dai safety framework esistenti, tutti costruiti per valutare tossicità e allucinazioni fattuali.
Le dinamiche di attaccamento non sono nel manuale.
🌐 Sul fronte geopolitico, il vantaggio USA si è quasi azzerato.
DeepSeek-R1 ha brevemente pareggiato il modello americano top a febbraio 2025.
A marzo 2026, il modello Anthropic guidava per soli 2.7 punti percentuali.
Il gap si è quasi chiuso, e lo ha fatto in modo drammaticamente rapido.
La Cina produce più paper, più citazioni, più brevetti industriali, più robot.
Gli USA producono ancora più modelli top-tier e brevetti ad alto impatto, ma il vantaggio strutturale si sta erodendo.
Nel frattempo, il numero di ricercatori AI che si spostano negli USA è crollato dell'89% dal 2017, con un -80% solo nell'ultimo anno.
Gli investimenti privati USA restano enormi ($285.9 miliardi, 23 volte la Cina), ma costruire un ecosistema di talenti non si fa solo con i capitali.
D’altro canto, gli USA ospitano 5.427 data center - un ordine di grandezza superiore a qualsiasi altro paese.
Ma quasi ogni chip AI che gira in quei data center è prodotto da una sola azienda, TSMC, in Taiwan.
È una fragilità sistemica che rende l'intera infrastruttura AI globale dipendente da un nodo geografico che chiunque segua le news geopolitiche conosce bene.
È il paradosso fisico dell'AI: un'industria che promette distribuzione, automazione e sovranità digitale costruita su una catena di approvvigionamento hardware più concentrata di qualsiasi commodity energetica.
📦 Il nodo irrisolto: capability ≠ governance.
Gli incidenti AI documentati sono saliti a 362 (erano 233 nel 2024).
Il Foundation Model Transparency Index è sceso da 58 a 40 punti in un anno - dopo essere salito da 37 a 58 l'anno prima.
I gap maggiori riguardano i dati di addestramento, il compute e l’impatto post-deployment.
In pratica, i modelli più potenti sono anche quelli di cui si sa meno e i cui vendor divulgano meno informazioni sul funzionamento.
Nel frattempo, il training di Grok 4 ha emesso 72.816 tonnellate di CO₂ equivalente (circa 17.000 auto per un anno).
La capacità dei data center AI ha raggiunto i 29.6 GW - paragonabile al consumo elettrico di picco dell'intero stato di New York in una giornata estiva.
L'inferenza annuale di GPT-4o da sola potrebbe superare il fabbisogno idrico di 12 milioni di persone.
Nessuna di queste cifre viene comunicata spontaneamente dai lab. Le sappiamo da ricercatori indipendenti.
E la valutazione per la Responsible AI? Quasi nessuno la fa sistematicamente.
Quasi tutti i lab pubblicano benchmark di capability, pochissimi pubblicano benchmark di safety in modo serio, riducendo la trasparenza.
E - ciliegina sulla torta - la ricerca mostra che migliorare la sicurezza spesso degrada l’accuratezza, e viceversa.
Purtroppo non è un problema tecnico che si risolve con più compute: è un trade-off strutturale che richiede scelte.
In pratica, i modelli AI diventano sempre più bravi a sembrare affidabili mentre diventano strutturalmente meno verificabili.
E quando gli strumenti che usi per misurare qualcosa smettono di funzionare, è normale che la fiducia cali.
E il pubblico - non a caso - ha smesso di fidarsi: negli USA solo il 31% si fida del proprio governo per regolamentare l'AI, il dato più basso tra tutti i paesi del campione.
A livello globale, l'UE è ritenuta più affidabile degli USA e della Cina per la governance AI.
E allora?
La risposta, ovviamente, non è smettere di usare l'AI, né ignorare i problemi.
È fare quello che i benchmark non fanno ancora: chiedere non solo quanto è capace, ma a chi risponde, di cosa è responsabile, e chi può verificarlo.
Cioè pretendere trasparenza e accountability.
La comunità tecnica sa costruire sistemi straordinari e strumenti per misurarli e valutarli.
La domanda è se quella volontà arriverà prima che il gap diventi incolmabile.
Nel frattempo, la cosa più utile che puoi fare è capire bene cosa stai usando.
Non per diffidare dell'AI, ma per usarla meglio, sapendo dove sono sia le valli, sia i picchi.
Intanto, se ti interessa uno sguardo più approfondito al report, ne abbiamo parlato profusamente anche in un nostro articolo e in una puntata di Algoritmi!

Giacomo Ciarlini - CIO - Datapizza
Simone Conversano - AI Transformation Specialist - Datapizza