15/01/2026Lessons from Testing Contextual Retrieval on Multiple Datasets
Table of Contents
- What is Contextual Retrieval and when should you use it?
- The core idea from Anthropic
- The problem it solves
- Our experimental setup
- Evaluation datasets
- Pipeline implementation
- Evaluation metrics
- Experiment 1: Contextual Retrieval vs Base Retrieval
- Setup
- Results
- Key takeaways
- Experiment 2: Adding a Reranker
- Why use a reranker?
- Rerankers we tested
- Results
- Key takeaways
- Conclusions
- What we learned
- When to use Contextual Retrieval
- Future work
What is Contextual Retrieval and when should you use it?
The core idea from Anthropic
Back in September 2024, Anthropic introduced Contextual Retrieval, a technique for improving retrieval quality in RAG systems. It addresses a common problem: when you extract chunks from a document, they often lose critical contextual information once separated from their original surroundings.
Here’s a concrete example from our D\&D dataset. Imagine a martial weapons table gets split across multiple chunks, leaving one chunk with just:
```
| Battleaxe | 1d8 Slashing | Versatile (1d10) | Topple | 4 lb. | 10 GP |
| Flail | 1d8 Bludgeoning | — | Sap | 2 lb. | 10 GP |
| Longsword | 1d8 Slashing | Versatile (1d10) | Sap | 3 lb. | 15 GP |
| Maul | 2d6 Bludgeoning | Heavy, Two-Handed | Topple | 10 lb. | 10 GP |
```
This chunk has all the stats for the maul, but it’s missing the table header that tells you these are Martial Melee Weapons. A semantic similarity search might completely miss this chunk when a user asks “Which martial weapon deals the most damage?”
Contextual Retrieval tackles this by enriching each chunk with a brief description that situates it within its source document. An LLM generates this context by looking at both the individual chunk and the full document, producing an accurate contextual summary. This context gets prepended to the chunk before embedding. We’ll dig into the details later in this post.
The problem it solves
Contextual retrieval shines when:
- Documents contain implicit references (pronouns, abbreviations, forward/backward references to other sections)
- A chunk’s meaning depends on where it sits in the document (technical manuals with thematic sections, regulations organized by chapter, product catalogs with categories)
- User queries are specific while chunks contain generic information
Anthropic reported significant retrieval improvements, especially when combined with reranking.
Why revisit this now?
It’s been over a year since that original post, which got us thinking: does Contextual Retrieval still hold up in 2026?
A lot has changed. The model landscape has evolved dramatically. Rerankers in particular have come a long way. Models like Cohere Rerank v4 Pro and newer open-source options from the Qwen 3 family deliver substantially better performance than what was available a year ago.
This raised an interesting question: how does Contextual Retrieval perform alongside modern rerankers and on challenging datasets? Does enriching chunks with context still provide meaningful gains? We ran the experiments to find out.
Our experimental setup
Evaluation datasets
We ran our experiments on:
- D\&D SRD 5.2.1, our public dataset from a previous blogpost, available on HuggingFace. Built with our rag-dataset-builder (GitHub), it contains 56 questions (25 easy, 31 medium) with ground truth labels for required chunks.
- Two private datasets under NDA, covering entirely different domains, to validate whether our findings generalize. We’ll refer to these as private dataset 1 and private dataset 2 throughout.
As we explained in the previous blogpost, our dataset’s character-based structure lets us precisely determine which chunks are needed to answer each question, regardless of chunking strategy.
Implementing our Contextual Retrieval pipeline
Contextual Retrieval modifies the ingestion phase: before inserting chunks into the vector store, you need to enrich them with contextual information that anchors them within the original document. This way, the embedding captures both the chunk content and its broader context.
We built our ingestion using the IngestionPipeline from Datapizza AI. This modular architecture lets us chain different processing steps as independent components: chunking, contextualization, embedding, and upserting to a vector store. We added custom components for LLM-based context generation.
Preprocessing
Our pipeline expects documents in markdown format. For PDF-to-markdown conversion, see the preprocessing steps in our rag-dataset-builder.
Chunking
For the D\&D SRD dataset, we kept things simple with character-based chunking:
- Chunk size: 4000 characters
- Overlap: 100 characters
Contextualization
This is where the magic happens. For each chunk, we feed an LLM:
- The full source document
- The chunk to contextualize
The LLM generates a brief context that we prepend to the chunk like this:
```
CONTEXT: [generated context]
CONTENT: [original chunk text]
```
Anthropic’s prompt (from their original blog post) looks like:
```
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within
the overall document for the purposes of improving search retrieval
of the chunk. Answer only with the succinct context and nothing else.
```
Our approach differs in a few ways:
- Model choice: We used Gemini 2.5 Flash to generate contexts, balancing quality against cost.
- Batching: To cut costs, we contextualize 10 chunks per API call instead of one at a time. This requires structured output that maps each chunk to its context.
- Domain-specific prompts: We created custom prompt templates for each dataset. Here’s our D\&D SRD template:
```
<document>
{{ whole_document }}
</document>
You are an expert on the Dungeons & Dragons 5.2.1 System Reference Document.
Your task is to contextualize text chunks for improved semantic search retrieval.
Key D&D 5th edition Concepts
- Core Rules: Ability Checks, Saving Throws, Attack Rolls, Combat Actions,
Conditions, Advantage/Disadvantage, modes of play. - Character Options: Races/Species, Backgrounds, Classes, Subclasses,
Feats, Spells, Equipment. - Dungeon Master Content: Monsters, NPCs, Traps, Hazards, Magic Items.
- Lore & Setting: Descriptions of the multiverse, planes, deities, factions.
Your Task
For each chunk below:
- Identify its primary category (e.g., "Fighter Class Feature", "Wizard Spell")
- Extract key distinguishing attributes from the document that may not be
in the chunk itself (level, rarity, components, prerequisites, etc.) - Write a single paragraph of context focused on helping a user searching
for this rule or item.
{% for chunk in chunks %}
<chunk id="{{ chunk.id }}">
{{ chunk.text }}
</chunk>
{% endfor %}
```
These domain-specific prompts help the LLM generate more accurate and relevant contexts.
With batching and Gemini Flash 2.5, contextualizing the entire D\&D SRD dataset cost around $0.63.
Embedding
We embed all chunks (with or without context) using Cohere embed-v4.0 (1536 dimensions).
Loading into Qdrant
After embedding, we load the chunks into Qdrant, our vector database of choice. Each chunk is stored with:
- The embedding vector (capturing both context and content)
- The original text (with and without context)
- Metadata (source document, character offsets, etc.)
The comparison pipeline
We set up two parallel pipelines for our experiments:
<!--IMG:0--><!--IMG:1-->
The only difference is the contextualization step, which lets us isolate its impact on performance.
Evaluation metric: Recall
We measured retrieval quality using recall.
In our setup, recall is the fraction of chunks needed to answer a query that the system actually retrieves. If a question requires 4 chunks and we retrieve 3 of them, that’s 0.75 recall.
To get a single metric for each dataset, we average recall across all questions at a fixed value of k (the number of chunks retrieved per query). With k=10, for example, the system returns the top 10 chunks by similarity, and we measure how many of those are actually needed to answer each question.
Experiment 1: Contextual Retrieval vs Base Retrieval
Setup
Our first experiment directly compares base retrieval against contextual retrieval, without any reranker. We tested k = 5, 10, and 20.
Embeddings were generated with Cohere embed-v4.0 (1536 dimensions), with similarity search on Qdrant for retrieval.
Results
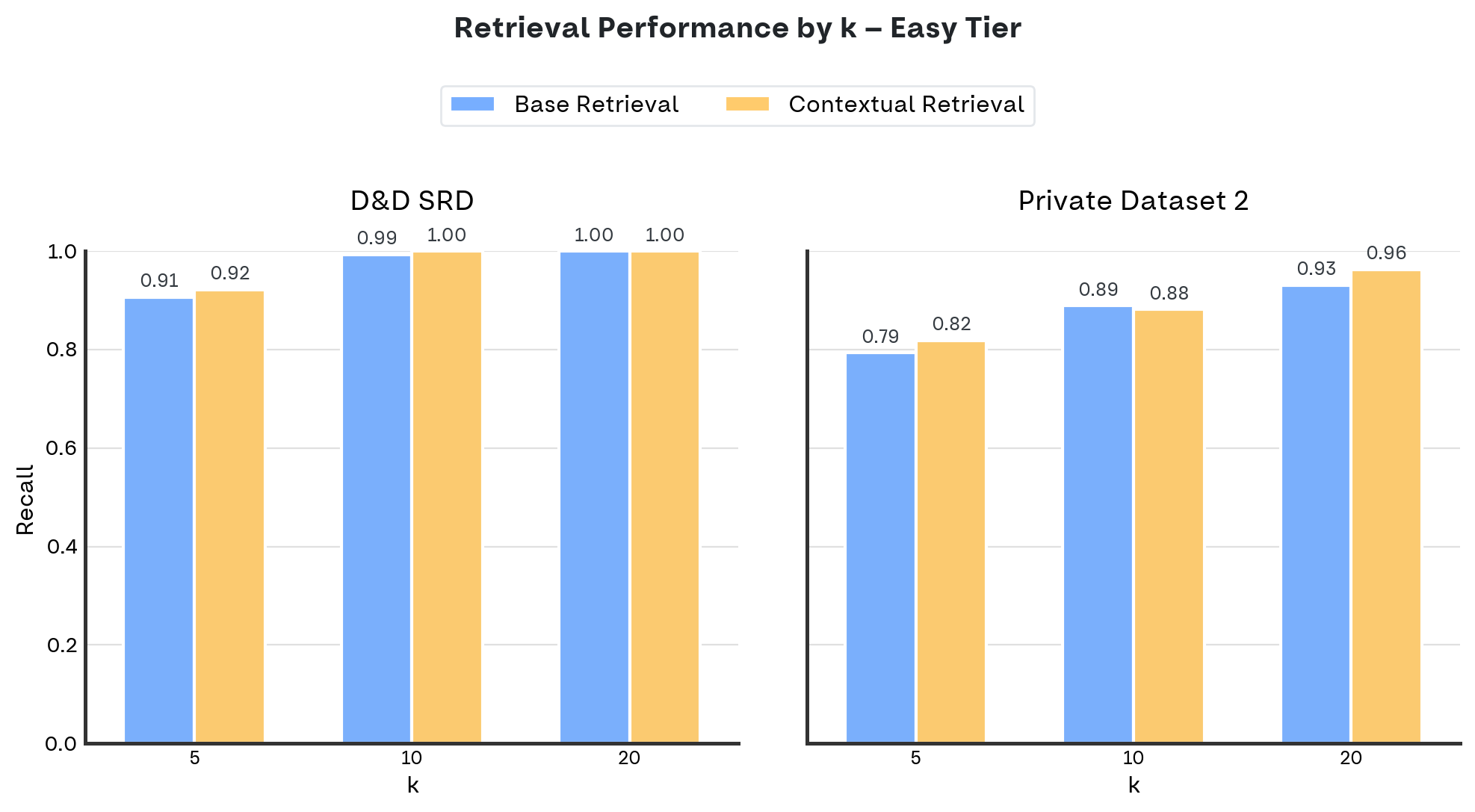
The charts below show recall (y-axis) across k = 5, 10, 20 (x-axis), comparing base retrieval against contextual retrieval.
For easy questions, we have results from two datasets: D\&D SRD and Private Dataset 2. Private Dataset 1 doesn’t include easy questions.
For medium questions, we have results across all three datasets: D\&D SRD, Private Dataset 1, and Private Dataset 2.
Each chart includes one subplot per dataset for direct comparison.
<!--IMG:5-->The table below shows the recall gain from contextual retrieval vs the baseline (recall_contextual − recall_base) at different k values:
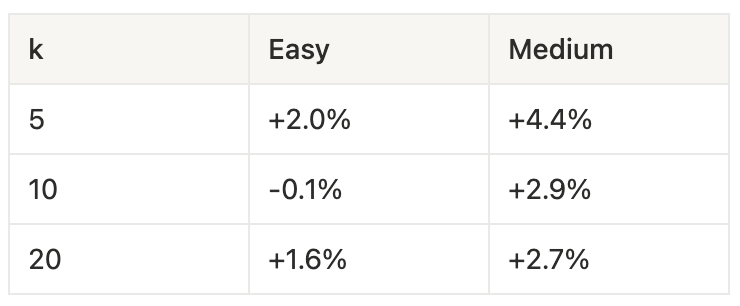
Something interesting emerges here: the biggest improvement happens at k=5, while k=10 shows minimal or even slightly negative gains.
One possible explanation: contextual retrieval may surface more relevant chunks overall. But with k capped at 10, some of these additional relevant chunks get cut off, reducing the advantage over the baseline.
To test this hypothesis, we plotted the average recall gain for every k from 1 to 20:
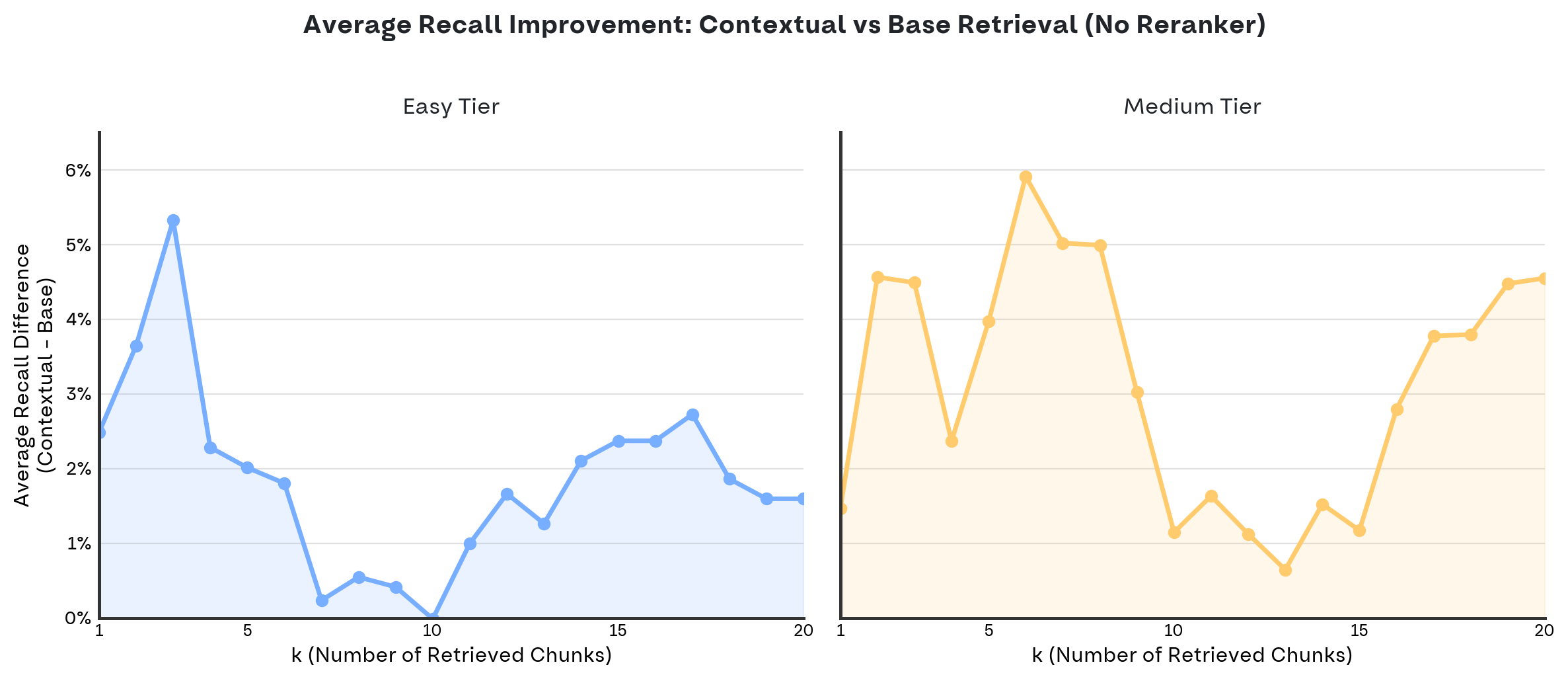
The graph confirms our hunch: for both Easy and Medium tiers, the gain bottoms out around k=10 and peaks at low k values. This suggests contextual retrieval is especially effective at pushing the most relevant chunks to the top of the ranking.
Key takeaways
- Consistent wins: Contextual retrieval outperforms the baseline in nearly every scenario we tested. Ties or slight losses are rare.
- Easy vs medium questions: Easy questions show modest gains because the baseline already performs well, often hitting 100% recall. Medium questions, being more challenging, show clearer advantages from contextualization.
- The k factor: Both approaches improve as k increases, but contextual retrieval maintains its edge. The relative gain is highest at low k (good for ranking quality) but dips around k=10, suggesting the added context may introduce some noise that becomes more noticeable in that range.
Experiment 2: Adding a Reranker
Why use a reranker?
We added a reranker to the pipeline for two reasons:
- Fair comparison with Anthropic: Their original blogpost used a reranker, and we wanted an apples-to-apples comparison.
- Testing a hypothesis: We suspected the added context might help the reranker distinguish relevant chunks from noise more effectively, since it sees the raw text and can leverage contextual information directly.
How the reranker pipeline works
Here’s the flow:
- Retriever (similarity search): Takes the embedded query and pulls p candidate chunks
- Reranker: Receives the query as plain text plus the p chunks, scores each query-chunk pair, and returns the top q chunks by score.
Unlike embedders that work with vector representations, rerankers analyze text directly, enabling more fine-grained relevance judgments.
Rerankers we tested
We evaluated two rerankers:
- Cohere Rerank v4 Pro: Cohere’s flagship reranker, released December 11, 2025. State-of-the-art quality.
- Qwen3 Reranker 8B: An open-weight model from Alibaba, the 8B base model fine-tuned for reranking. Our setup:
This gives us a self-hosted reranker with low costs and no external API dependencies. 1. Deployed on Scaleway with an L4 GPU (24GB VRAM) 2. Ran a vLLM container to serve the model 3. Connected via OpenAI-compatible API using Datapizza AI
Results
Here are the medium-difficulty recall results with k=20:<!--IMG:6-->
We also applied the same analysis from Experiment 1 to examine recall gains (recall_contextual − recall_base) across all k values from 1 to 20:
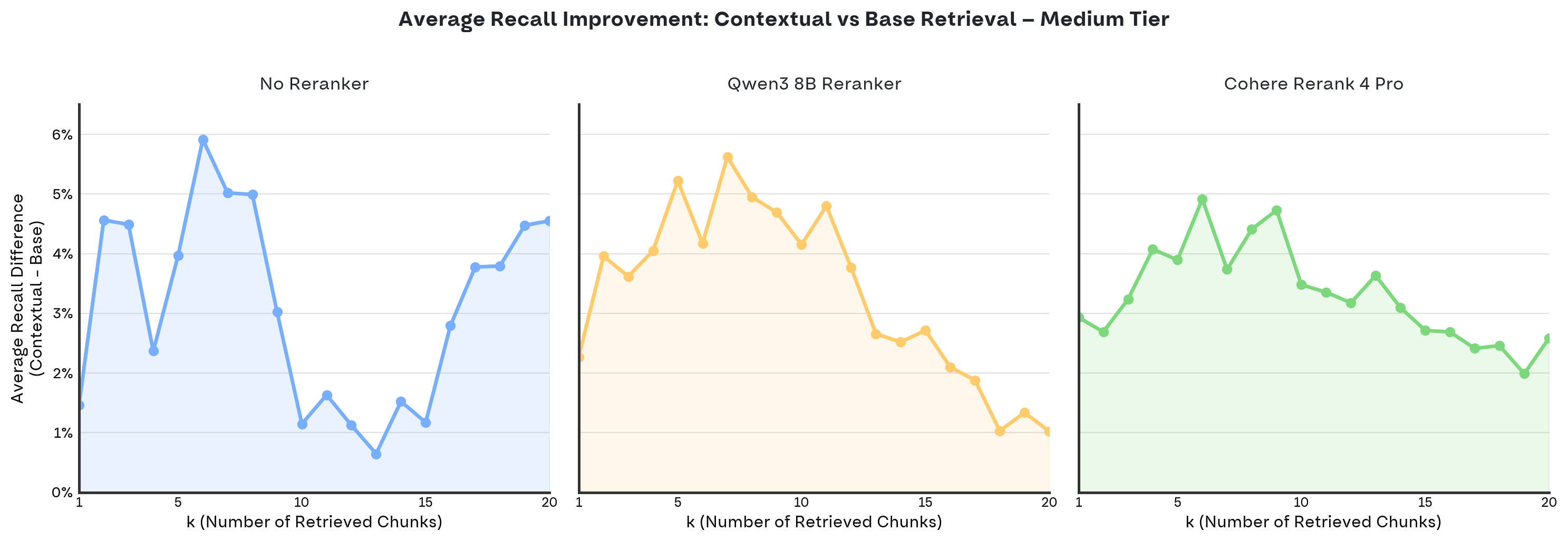
With a reranker in the mix, the dip around k=10 disappears. Instead, we see peak improvement around k=5, with gains tapering off at higher k values. This makes sense: as k grows, there’s less room for contextual retrieval to add value.
Key takeaways
- Rerankers help across the board: Adding a reranker significantly improves both base and contextual pipelines.
- Contextual still wins: Even with a reranker, contextual retrieval beats the baseline in almost every scenario. The one exception was Private Dataset 1 with Qwen3 Reranker 8B. This was predictable given that dataset’s messy structure and suboptimal chunking. An edge case, not a trend.
- Smoother performance across k: The reranker stabilizes gains across different k values, eliminating the dip around k=10. This points to good synergy between contextualization and reranking—together they reduce noise in retrieved results. The biggest gains still cluster around k=5, confirming that contextual retrieval excels at ranking. At higher k, some of the contextualization benefit seems to get “absorbed” by the reranker.
Conclusions
What we learned
After running these experiments, here’s what we took away:
- Contextual Retrieval still works: Across all three datasets, contextualization consistently improved performance.
- Bigger but less stable gains without a reranker: If you’re not using a reranker, contextual retrieval delivers a solid boost, particularly at higher k values. With a reranker, overall quality improves (even for the baseline), and results are more stable across k—peaking around k=5.
- Hard questions stay hard: Even with contextualization and reranking, medium-tier questions remain challenging. There’s room for more sophisticated approaches.
When to use Contextual Retrieval
Use it when:
- You can handle higher ingestion costs (around $0.63 in our case, since each chunk needs an LLM call)
- Your documents have lots of implicit references or rely heavily on context
- You have a specific domain where you can craft optimized prompt templates
Skip it if:
- Ingestion costs are a hard constraint
- Your chunking approach doesn’t lend itself to contextualization
- Your chunks are already self-explanatory and standalone
Future work
Several directions look promising:
- Hybrid search: Combining BM25 or other lexical methods with semantic similarity
- Chunking strategies: Testing different approaches (semantic, sentence-based, LLM-driven, etc.)
- Prompt template variations: Comparing different contextualization prompts
- Multimodal Contextual Retrieval: Extending contextualization to handle images and other input types
- Larger batch sizes: Pushing beyond 10 chunks per batch and systematically measuring the cost/quality tradeoff
All the code for these experiments is available in our GitHub repository.
***
*Raul Singh —* GitHub — LinkedIn — AI R\&D Engineer @ Datapizza
*Ling Xuan “Emma” Chen —* GitHub — LinkedIn — AI R\&D Engineer @ Datapizza
*Francesco Foresi —* GitHub — LinkedIn — GenAI R\&D Team Lead @ Datapizza