04/02/2025Guida al prompting di DeepSeek e O1
Negli ultimi giorni si parla molto di modelli di reasoning nel mondo dell’AI…
DeepSeek ha rilasciato R1. 💡
OpenAI ha rilasciato o3-mini e o3-mini high. 🙌
Mark Zuckerberg ha annunciato novità su Llama 4, anticipando futuri rilasci di modelli di reasoning anche da parte di Meta. 👀
Dato che sempre più persone utilizzano i modelli di reasoning, volevo condividere con te questa guida su come utilizzarli al meglio. 📚
Ma facciamo un breve passo indietro…
Come funzionano? 🤔
Per spiegartelo in breve, il modello genera più risposte in parallelo e confronta diverse opzioni di completamento prima di rispondere (Test Time Compute). ⌛️
Questo genera un comportamento di “ragionamento interno”, che gli permette di risolvere problemi più complessi e di logica.
Ora torniamo a noi.
Molte persone non sono soddisfatte dell’output che ottengono utilizzando questi modelli.
Il problema è che tendiamo a trattarli come abbiamo sempre fatto con modelli come GPT-4o o Claude Sonnet 3.5 … che, però, funzionano in maniera diversa …
È importante capire che modelli come o1 non sono “modelli di chat**”**. 💬

Ti spiego meglio. 👇
Da quando abbiamo a disposizione strumenti come ChatGPT, ci siamo abituati a ricevere una risposta in output molto velocemente. ⌨️
Ma con i modelli di reasoning la velocità di risposta (tempo di latenza) è cambiata. ⏱️
Il modello ci mette più tempo prima di darti una risposta in output. Proprio perché si prende del tempo per “ragionare” (siamo sempre restii nell’usare questo termine perché i modelli non ragionano come facciamo noi) 😅
Ecco alcuni punti chiave per sfruttare al massimo le capacità di questi modelli 🗝️
1️⃣ Fornisci molto contesto e definisci in maniera chiara l’output che vuoi per ottenere la soluzione giusta al primo colpo
In breve, è importante fornire un brief chiaro e tantissimo contesto.
Qualunque cosa pensi sia “tanto”, tu moltiplicalo x10 😂
Ecco un esempio di prompt:

Torniamo a parlare per un secondo dei modelli classici che conosciamo, come Claude 3.5 Sonnet o GPT-4o.
Immagino che quando usi questi modelli inizi facendo una domanda semplice e aggiungendo una breve frase per dare contesto. 📩
Poi se il modello ha bisogno di più contesto, spesso te lo chiederà.
Di base è un botta e risposta fino a quando ottieni l'output desiderato. ✅
Con i modelli di reasoning, invece, devi dare tantissimo contesto in partenza.
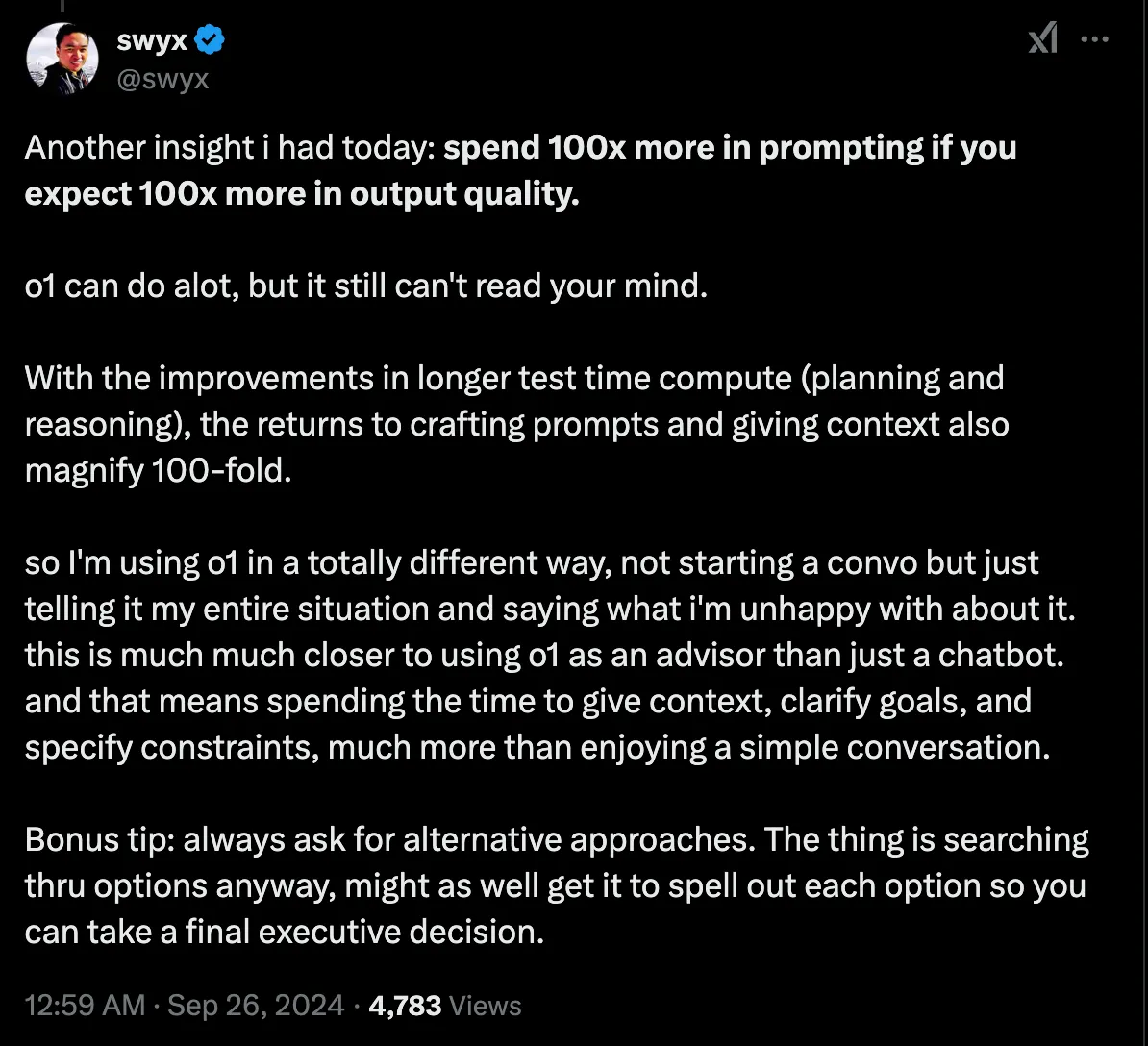
Un piccolo trick utile potrebbe essere:
👉 usare app di registrazione vocale per descrivere tutto il problema in 1-2 minuti di audio e poi incollare la trascrizione.
2️⃣ Concentrati sugli Obiettivi: descrivi esattamente cosa vuoi all'inizio, e concentrati meno su come lo vuoi
Quindi prima fornisci più contesto possibile.
Poi spiega che cosa vuoi nell’output.
Con la maggior parte dei modelli, siamo stati abituati a dire al modello in partenza come vogliamo che ci risponda:
“Sei un esperto in software engineering.”
“Pensa lentamente e più attentamente prima di rispondere”
Ecco, con o1 dobbiamo usare il meccanismo opposto. 🔄
Non devi dargli istruzione sul COME fare una cosa ma solo su CHE COSA deve fare.
Poi lascia che faccia tutto o1.

Ecco questa è una breve guida su come utilizzare i modelli di reasoning ed evitare di perdere tempo e agitarsi perché non ci risponde come vogliamo 😂
È importante, secondo me, capire che i modelli di reasoning hanno performance molto buone per determinati compiti, ma non sono migliori in assoluto.
Devi fare un’analisi step-by-step di un codice molto lungo? 👉 allora o1 potrebbe essere molto utile.
Hai una domanda diretta come “qual è la capitale dell’Argentina?” 👉 allora meglio GPT-4o.
Ma aspetta, non ho finito, ho ancora un paio di cose da dirti 😂
Ieri OpenAI ha annunciato Deep Research, nuova funzionalità di ChatGPT in grado di eseguire ricerche complesse e dettagliate, utilizzando il modello o3 per navigare sul web e analizzare dati con precisione.

Questa funzionalità sarà disponibile inizialmente per gli utenti Pro (con l’abbonamento da $200 al mese). 💸
Ne parleremo meglio della nuova funzionalità nei prossimi giorni sui nostri canali.
Nel frattempo volevo anticipartelo. 👀
PS: giovedì scorso abbiamo fatto una live su DeepSeek.

Se l’hai seguita, saprai che ho promesso di lasciare le slide in questa puntata di Commit.
E infatti eccole qui! 💪
E se vuoi recuperare la live, la trovi su YouTube a questo link! È stato assurdo, c’erano più di 400 persone, non me lo aspettavo… 😱
By Giacomo Ciarlini - Head of Content & Education - Datapizza